Ududtoto – Kenaikan basis data vektor seiring dengan kemajuan pesat kecerdasan buatan generatif telah menarik perhatian berbagai perusahaan untuk mengintegrasikan teknologi ini ke dalam kegiatan bisnis mereka. Salah satu pendekatan yang umum digunakan adalah membangun sistem AI yang dapat menjawab pertanyaan berdasarkan informasi yang tertuang dalam basis data dokumen. Banyak solusi memanfaatkan teknik Retrieval Augmented Generation (RAG), yang bertujuan untuk mengambil dokumen relevan dan menghasilkan respons berdasarkan informasi tersebut.
Sistem RAG menggunakan “embedding” untuk menentukan relevansi dokumen, melalui representasi vektor yang mencerminkan kemiripan. Seiring meningkatnya penggunaan RAG, basis data vektor muncul sebagai jenis basis data terbaru yang dirancang untuk menyimpan dan mencari ribuan embedding. Sejumlah startup telah menerima investasi yang signifikan untuk memfasilitasi kemudahan pencarian embedding, mengingat efektivitas RAG yang mendorong banyak aplikasi baru.
Namun, penyimpanan embedding menimbulkan tantangan tersendiri. Vektor yang dihasilkan tidak dapat dengan mudah dipahami manusia dan berisi angka-angka yang tidak memiliki makna langsung. Kualitas keamanan data pun menjadi pertanyaan, terutama jika terjadi pembobolan data atau penyalahgunaan oleh penyedia layanan.
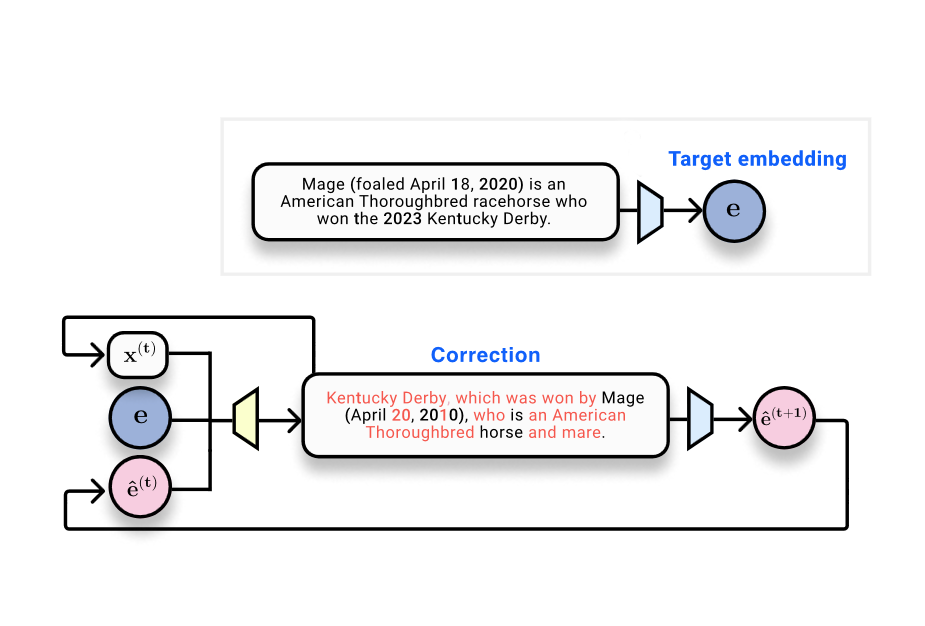
Penelitian terkini menunjukkan bahwa embedding dapat mengungkap informasi sebanyak teks aslinya. Meskipun embedding bertujuan untuk menyederhanakan penyimpanan informasi, potensi pemulihan teks dari embedding menjadi wilayah eksplorasi yang kritis. Metode baru, seperti yang diberi nama vec2text, telah dikembangkan untuk memaksimalkan pengembalian informasi dari embedding, menunjukkan keberhasilan dalam menghasilkan kembali teks dengan akurasi tinggi.
Dengan perkembangan ini, masa depan basis data vektor dan teknik embedding menuntut perhatian lebih lanjut mengenai keamanan dan efektivitas pemanfaatan teknologi AI dalam berbagai bidang.